Decentralization Principles for Data Spaces¶
The benefit of decentralized data spaces¶
In an era defined by rapid digital transformation and complex data ecosystems, the architecture of data spaces must empower participants with maximum autonomy and agency to support their digital sovereignty. IDSA recommends decentralized data space architectures as the recommended approach because they best preserve participant control, equal treatment, and robust interoperability. Alternative architectures may be used where operational or regulatory constraints justify them, but any departure from decentralization must be documented and the impact on participant autonomy mitigated by the DSGA.
The core principles and practical advantages of decentralization in data spaces are well aligned with the ISO 20151 - “data space concepts and characteristics” standard.
Maximising Participant Autonomy and Agency (Sovereignty)¶
At the heart of decentralized data space architecture is the principle of participant autonomy and agency. Each organisation or entity operates independently, and is fully capable of deciding when to share which data assets with whom, under what circumstances and which rules apply to the usage of the shared data. Participants are managing their own credentials describing their identity, without reliance on an external party controlling the their identity through a singular identity provider. They manage their interactions without centralized authorities or services. Where external or centralized components are required (for regulatory, operational, or other justified reasons), the DSGA must document the rationale and specify mitigation measures to preserve participant autonomy and choice. This approach protects digital sovereignty, allowing participants to decide how, when, and with whom their data is shared — critical for compliance, privacy, and strategic control.
Protocols for Interoperability: Leveraging DSP and DCP¶
Interoperability is essential for data spaces to function as collaborative, decentralized meshes of participants. With software agent (e.g. connectors) implementations leveraging Data Space Protocol (DSP) and Decentralized Claims Protocol (DCP) to facilitate seamless, standardised interactions between participants.
Technical interoperability between individual participants can be guaranteed irrespective of the data space which is operating as a governance and business context on top of the mesh of participants. These protocols enable software agents (e.g. connectors) to exchange data and services without vendor lock-in, ensuring that integrations remain flexible, secure, and future-proof.
Let’s revisit the mental model of layers of a data space. At the technical layer a data space consists of a decentralized mesh of individual nodes, which are acting with full autonomy and agency. Only in the higher layers of business and legislation processes the segmentation into separated trust contexts are manifesting. Such trust contexts can be “strong borders”, representing boundaries between data spaces in different nations, but also can be “weaker borders”, representing a segmentation into individual use cases within a data space. No matter where the segmentation takes place, all use cases are unified by the common, interoperable technology, founded on a solid base of the DSP and DCP.
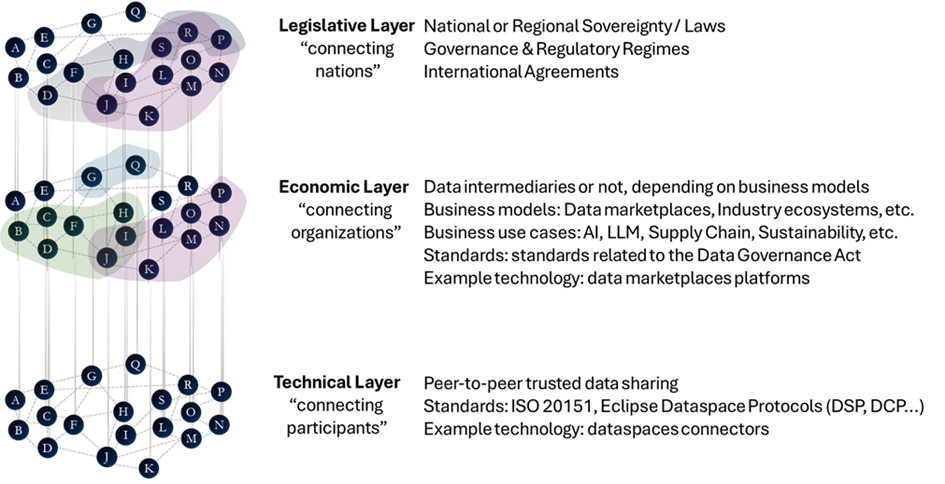
Roles in the data space: Governance Authority and Participant¶
As described in the chapter on Roles Decentralized data space architectures define only two essential roles: the Data space Governance Authority (DSGA) and the Participant. The DSGA establishes rules and specifies which Dataspace Trust Frameworks (DTFs) will be used, who operates the accepted Onboarding Services and which mandatory business processes exist, while participants actively engage in the data space to negotiate data sharing contracts and execute existing agreements. Notably, service provider organisations can host governance and onboarding services, providing the necessary legal and business frameworks for onboarding and compliance.
Any business role within the data space, e.g. Provider, Consumer, Auditor, Marketplace, and many others can be built as a specialisation of the technical role of the participant.
There is no need for custom technical architectures or specialised protocols to satisfy those business roles and their requirements. No additional architectural components (e.g. central or federated catalogs, identity providers, etc…) are needed to create an operational data space. On the contrary, adding such special architectural components reintroduces centralization and fragility to the data spaces and becomes a single point of control and potential failure, very often resulting in performance bottlenecks or preferred attack points during cybersecurity events.
Trust Frameworks and Credential Management¶
Trust within the data space is governed by at least one Dataspace Trust Framework (DTF). DTFs contain the rules that are fundamental to trust creation within the data space. An empty DTF/no DTF also qualifies as a DTF as no rules can be interpreted as data being shared with anyone without conditions (e.g.: Open Data).
DTFs can be built hierachically by partial DTFs, external DTFs, DTF building blocks, etc. It is the responsibility of the DSGA and/or the participant to resolve any potential conflicts between the applied DTFs and to ensure a final, unambiguous set of rules. If a data asset is offered under two different rule sets, it shall be treated as two separate contract offers.
Instead of maintaining membership lists, the architecture relies on onboarding credentials — requested/issued and managed by participants themselves, checked and validated by onboarding services and signed by signatory services, the credential issuance service of the DTFs. This model ensures that each participant is responsible for their own credential lifecycle, promoting autonomy and reducing administrative overhead.
The model also assumes that the membership criteria set by the DSGA can be expressed as verifiable credentials, and that the dynamic nature of both membership criteria and credentials is taken into account.
Credential verification is handled on-demand, reinforcing the decentralized nature of the data space and minimising the risk of single points of failure or control.
Advanced Business Functions: Mapping to Participant Roles¶
Advanced business cases such as participant matching, observer roles, and data marketplaces can be easily mapped to the participant role. For example:
- Marketplace/Matching Participants: Multiple participants can provide a service that allows the discovery of and connection with other participants using catalogs and vocabularies, without central mediation. Each participant that wants to participate in a marketplace or a matching service shares their metadata through a data sharing contract with the Marketplace/Matching Service Provider Participant, who then in return will offer a data sharing contract with the potential matches. All within the rules of the data space, ensuring that autonomy and agency is preserved. Having multiple, independent such Service Providers will greatly enhance the freedom of choice and resiliency of the data ecosystem.
- Observers: Entities wishing to observe or audit interactions within the data space can do so by joining as participants with observer-specific credentials. Participants that are negotiating a contract that requires auditing can then both negotiate a data sharing agreement with the Observer participant to share their individual log files of the transaction. The Observer will provide the service of auditing and reconciling those log files and in return issue a data sharing agreement with the two participants where the results of the audit will be shared. Again, all perfectly within the rules and processes of the data space, fully preserving participant autonomy and agency.
- Data Escrow Service Providers: Data escrow operations are managed by participants acting as service providers, who are offering a trusted data escrow environment - a confidential compute environment where two or more participants can share their data and have computation being performed on the data without any of those participants ever having access to all data at once. The Data Escrow Service Provider participant guarantees the operation of the environment, and the distribution of results. With special encryption methods it can also be guaranteed that the Data Escrow Service Provider never gets to see the actual data. This is enabling joint analysis of data while ensuring the highest level of data privacy. E.g., in medical research scenarios or financial services.
When designing the data space business functions it is important to pay attention that the introduction of mandatory value-added services might introduce unwanted centralization or federation thus leading to undesirable concentration of control and accidental single point of failures/attack that can negatively affect the participants in the data space. It is highly recommended to enable an open market of competing value-added services to ensure higher resiliency and avoid centralization of control.
Global data space mesh¶
As decentralized architectures proliferate, a global mesh of data space agents (e.g. connectors) is a long-term target state and is beginning to emerge incrementally. Each data space maintains its own legal and trust boundaries, ensuring that governance and compliance are localised and context-specific. At the same time, the underlying technologies - agents, protocols, credential management systems - are reusable across multiple data spaces, maximising efficiency and reducing duplication. This mesh enables organisations to participate in multiple data spaces seamlessly, leveraging consistent standards and interoperable technologies.
Use Case Segmentation¶
Segmentation within the data space is achieved via use case specific credentials which might be issued by credential issuers that are providing specialised DTFs for a specific use case. For instance, in the automotive supply chain, manufacturers, suppliers, and logistics providers each hold credentials tailored to their role and use case. Use cases could be anything from specific business processes, regulatory requirements to smaller communities created by the supply chain of a specific company. This segmentation ensures that data access, sharing, and collaboration are precisely controlled, supporting advanced business models such as just-in-time delivery, quality assurance, and regulatory compliance.
Decentralization as the default¶
A fully decentralized data space architecture delivers unmatched benefits in participant autonomy, digital sovereignty, and interoperability. By aligning with ISO 20151, leveraging DSP and DCP protocols, and streamlining roles and credential management, organisations can build robust, flexible, and future-ready data ecosystems. As the global mesh expands and technology is reused across domains, the potential for innovation and collaboration grows exponentially. Segmentation via use case specific credentials ensures that each participant operates within precise trust boundaries and as effectively as possible, paving the way for the next generation of digital business.